This talk is focused on a project my colleagues and I have been developing over the past year called uw-spring-security. uw-spring-security is a multi-module Java project that University of Wisconsin applications can use to secure web applications in a way that is compatible not only with our single-sign-on technology, Shibboleth, but how we deploy it.
I have used Spring Security for many years, and in my opinion, it is exceptional. It has comprehensive support for all things authentication and authorization. The only drawback: it is terribly difficult to get started with. The reference manual is 36 chapters. Just the getting started chapter (chapter 3) is a long read, and the topics covered aren’t relevant to what University of Wisconsin Java developers need to know.
Pairing Spring Security with the way we deploy Shibboleth is not intuitive. uw-spring-security addresses that by replacing the boilerplate configuration classes described in the Spring Security reference manual with:
Determining whether Shibboleth (pre-authentication) is enabled or a local login form is used is accomplished by activating one (or both) of the 2 Spring @Profiles the library supports: preauth or local-users, respectively. Both profiles present the exact same data model for a User:
This library has been immensely useful within my group, and now it is time to share with a wider audience.
This library paired with uw-frame and rest-proxy gives us all we need to create business applications in My UW Madison. These 3 components provide all of the application middleware, and allow us to write user interfaces simply with HTML, JavaScript and AngularJS.
Looking back at that original post, I think the video does a good job of showing collaboration, but I think it falls short in demonstrating the actual size of the assets we manage. Each of the dots is a file, but no dot is larger than any other. I don’t think it’s fair to show a 20 line file and a 10,000 line file as having the same size.
This new approach tries to relate the size of our projects’ codebases to the novel Anna Karenina by Leo Tolstoy. There are a lot of similarities to made between writing code and authoring a novel. I think we all have a reference point of the mental effort and time required to read a novel. It’s not a stretch to relate those same mental activities to reading code - either someone else’s or even our own from a few months back. With contemporary sofware engineering tools and techniques, the scale of what an engineer needs to understand escalates exponentially.
This talk’s first audience includes the leadership of my current organization. My hope for presenting the talk is to recommend a few ideas regarding how we maintain our software projects:
Be more transparent. Code really should be visible at the organization level. We gain nothing by hiding from ourselves, we only introduce a high potential cost that is realized with staff change - not just turnover, but re-assignment too.
Write more that isn’t “code.” Executable/deployed code by itself is only a small part of IT solution delivery. Without context, that code can be unintelligible, as the last slide in the bonus code samples. Documentation and unit/integration/e2e tests are really the things that capture the business need of why we worked on a project in the first place, and can even persist through multiple different implementations. Version control history is critical too, because it lets us capture what we’ve tried before, particularly when we write good commit messages.
Curate. Dedicate more time to keeping things buildable, deployable, repeatable. If we’ve done 1 and 2, it will be easier for groups with cross cutting focus (deployment, security, testing) to interact with our IT solutions. That can even facilitate those groups contributing fixes or patches without waiting for a developer to be available to unlock access to the code.
Additional Resources
Google presentation on the scale of their codebase. Watch this video, it’s worth the 30 minutes. Teaser: Google’s internal source is managed in one large repository, shared with the company, with over 1 billion files and over 2 billion lines of code. That is 46,296 Anna Kareninas.
As the technical lead for a team of engineers, I’m regularly tasked with explaining or justifying the effort behind custom software development projects, from “small” to “large.”
There are a numberofdifferent methodologies for describing the relative difference between a small and a large effort in technical terms, but those methods are lacking in clarity for a non-technical observer.
Some projects have an incredibly large but simple feature set that can be provided with a relatively small code base. Other projects have a seemingly tiny feature set, but have enormous complexity and large amounts of code. To a non-technical observer, it can be difficult to comprehend how a seemingly “small” web site can require so much development effort to deliver.
Visualizing Relative Scale
I’ve known about the existence of a tool called Gource for some time, and experimented with it a few times. I had an idea recently to use Gource to demonstrate:
relative size and complexity of the projects in our portfolio, and
how our engineers work together on those projects
My hypothesis: a visual representation of the activity of the team may provide a non-technical observer a better understanding of the relative difference of effort between software projects.
Part of my team’s current portfolio is made up of about two dozen different independent software projects, primarily web applications. Those applications are composed of different technologies and are different stages of the lifecycle, from green field through end of life.
Here is the output from Gource on the combined activity for those two dozen projects between June 2014 and late October 2015:
Description:
Internal Applications team members are shown using their avatars. Non-team members are represented with the little chess piece icon.
Department and division web sites my team regularly constructs are not included in this demonstration.
Each path radiating from the center point represents a different project in our portfolio.
Each leaf dot is a file within the project, only file extensions are shown to show the diversity of languages and content we must produce.
Each laser beam from an avatar to one or more dots represents an individuals contribution; each bug fix or feature we develop results in adding or removing 1 to thousands of files.
On Monday, August 17, 2015 we imported a software project that has been maintained without verson control for more than a decade. The primary developer for that project transferred from another part of the organization to our team a few weeks prior.
My Takeaways
Collaborative development provides enormous value to a project, particularly as the project increases in size. Any engineer from our team - and even engineers outside of our team - should be able to contribute to any project in our portfolio. I will write a future article on the technology strategy and tools we use to accomplish that. You can see each multiple different members contributing to each of the different projects and pathways.
Our biggest challenge: our engineers are outnumbered by projects. This video could look completely different:
If each engineer worked solo on projects, their avatar would stick on top of one portion of the tree and never move. We would never have the benefit of different perspectives contributing across the portfolio, and we’d have difficulty in cross training or filling gaps if an employee leaves.
August 17, 2015 is a watershed moment for our team. As demonstrated by the video, the sheer size of that project is greater than all of our existing projects (in version control) combined. Simply switching from a single-developer to a collaborative model is no small feat for this project, it will take us significant time and effort to transition that project.
I hope to re-visit this technique on a yearly basis.
Each time I go a long stretch without publishing a Maven artifact via Sonatype, I find it’s easy to trip up on the GPG configuration, particularly on Mac OS X. I’m recording this here so hopefully the next time it’s a little easier.
We need to pass properties into the maven-gpg-plugin. Putting them in the project’s pom is a terrible idea, and passing them on the command line is awkward.
<profile><id>gpg</id><activation><activeByDefault>true</activeByDefault></activation><properties><gpg.useagent>true</gpg.useagent><!-- gpg-plugin defaults to trying 'gpg' on the path, this changes that to 'gpg2' instead --><gpg.executable>gpg2</gpg.executable><!-- <gpg.passphrase>secret-passphrase-here</gpg.passphrase> --></properties></profile>
Note the commented out property. There is a step during the Maven release perform goal where the gpg-plugin runs that will sign the artifacts generated for the module(s). If your key is encrypted with a passphrase, a prompt will appear. stdin for this prompt isn’t reachable, so you have no way to enter your passphrase, and the perform goal will fail.
You have 2 choices here:
Set gpg.useagent to false, and keep a plaintext copy of your passphrase in this file.
Set gpg.useagent to true, and remember to interact with the gpg-agent before running the Maven Release so that it can cache your passphrase.
Use your best judgment on what you are comfortable doing with your passphrase.
You’ll be prompted by gpg for your passphrase. Upon success, you’ll see another file with .asc extension next to the tempfile.
Now the gpg-agent in this terminal session has your passphrase. If you repeat the steps, you’ll note you don’t get asked again for the passphrase! Now run the Maven release process (mvn release:prepare, mvn release:perform) in the same terminal session.
The premise behind the talk is to describe why, and to some extent how, to include “Software Releases” within your Continuous Delivery pipeline. A Software Release isn’t the same thing as “deploying/shipping/rolling out” to any particular environment; those verbs are the action you perform on the deployable thing that the release creates.
I think releases are an important step for a few reasons:
Releases are really easy to make and cost nothing.
Releases also give you a repeatable way to deploy any milestone of your project; going back to any particular state is a lot easier, and doesn’t depend on a single individual or a data recovery system.
A lot of this is covered in the presentation and the notes. What’s not shown in the slide deck is the tour of my team’s chosen tools to perform release management.
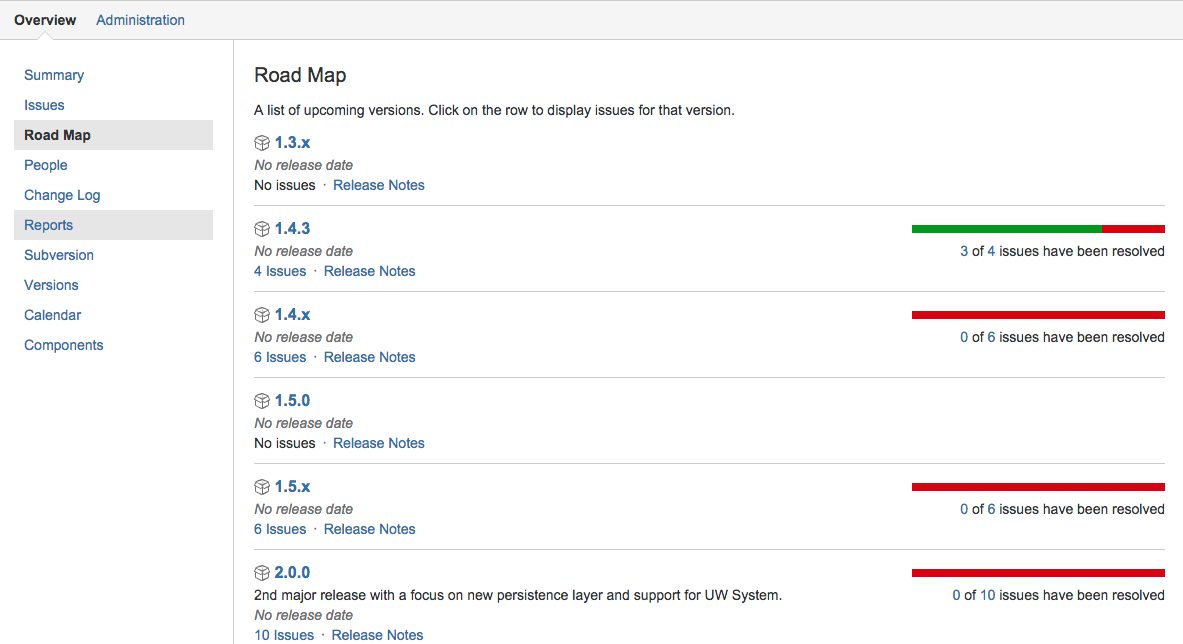
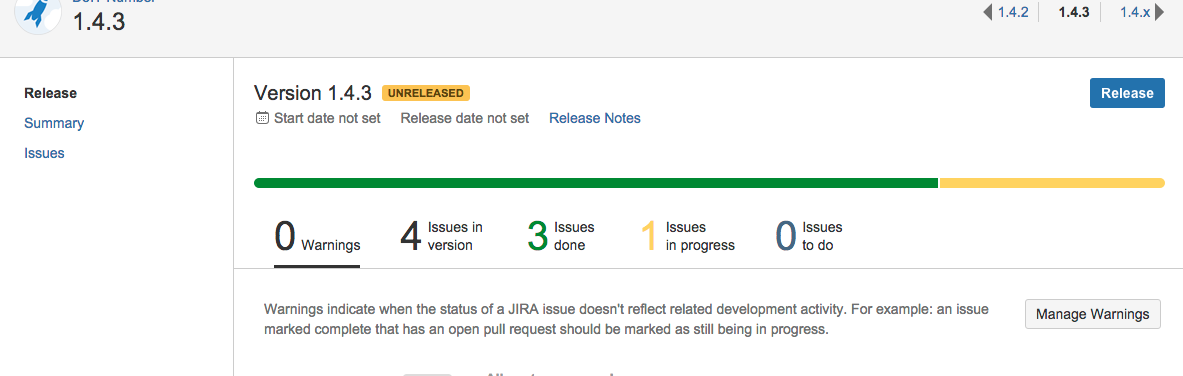
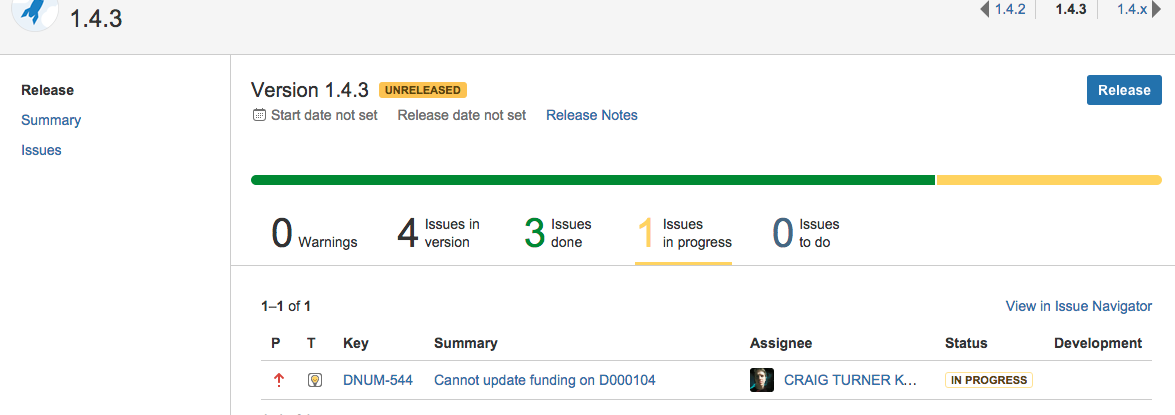
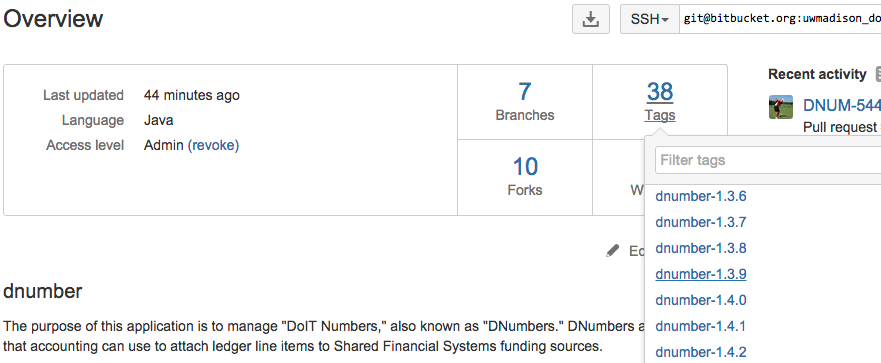
Screenshot Tour
Here are some screenshots of JIRA (task tracker and project management), Bitbucket (git version control), and Sonatype (artifact repository)